さささ昨日の続きです。現実逃避にもってこいの世界線にすっかり夢中になっています。多謝!
お世話になり続けているスターサーバなのですが、SSH接続ができません・・・
なのでしばらくサーバでのリリースはほっておき
その代わりにGitHubにUpしてみたいと思います。
GitHubでは、Pythonプロジェクトのコードやリソースを共有することができます。
また、README.mdファイルに実行環境の構築手順を記述することが一般的だそうなので
さっそくレガシーを消去して新しいレポジトリをREADMEとともに作成しました
#filename #requirements.txt
pytesseract
Pillow
pandas
spacy
ipywidgets
#filename #app.py
import pytesseract
from PIL import Image
import pandas as pd
import spacy
import io
from IPython.display import display, HTML
import ipywidgets as widgets
import urllib.parse
# Tesseractのパスを指定(必要に応じて変更してください)
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 日本語モデルをロード
nlp = spacy.load("ja_core_news_sm")
# 画像をアップロードするためのウィジェット
file_upload = widgets.FileUpload(accept='.png, .jpg, .jpeg', multiple=False)
# アップロードされた画像を処理して表示する関数
def process_uploaded_image(change):
uploaded_file = list(change['new'].values())[0]
image_data = uploaded_file['content']
image = Image.open(io.BytesIO(image_data))
display(image)
text = pytesseract.image_to_string(image, lang='jpn')
print("OCRで認識されたテキスト:")
print(text)
data = [{'記事ID': 1, '記事タイトル': 'OCR結果', '作成者': 'ユーザー', '作成日': '2024-10-02', '内容': text, 'コメント': ''}]
df = pd.DataFrame(data)
html_table = df.to_html(index=False, escape=False)
display(HTML(html_table))
csv_data = df.to_csv(index=False, encoding='utf-8')
csv_data = urllib.parse.quote(csv_data)
download_link = f'<a href="data:text/csv;charset=utf-8,{csv_data}" download="ocr_results.csv">ダウンロード</a>'
display(HTML(download_link))
file_upload.observe(process_uploaded_image, names='value')
display(file_upload)
この後にTesseractをローカルでインストールします。
https://tesseract-ocr.github.io/tessdoc/Compiling.html#windows
こちらがTesseractのDLページです。ダウンロードしたくない病発症するページです

実際このページは何だったのかわかりません。実行するときも危険とでます。注意
テッセラクトTesseract
このDLは結構一筋縄ではいかなかったのでドキュメントにして残します。
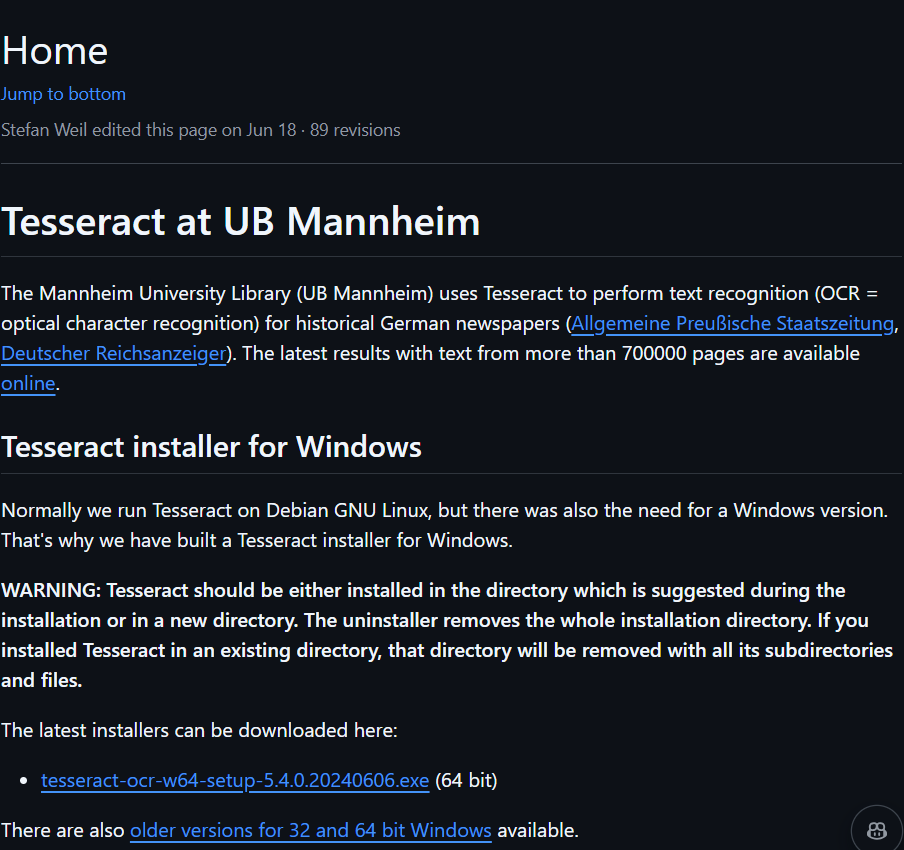
マンハイム大学図書館 (UB Mannheim)の開発したもの?いずれにせよ70万ページのテキストがオンラインで入手できるそうです。ドイツの歴史的な新聞の内容だそうで、大変意味深いですね。
https://zenn.dev/tetunori/books/20240907-tetunori-tesseract/viewer/buildenv
こちらダウンロードの参考資料です。
インストーラーからC:\Program Files\Tesseract-OCRにインストールができました。
実行できているのか以下のコードで確認しました
最初、インストールされているにもかかわらずコマンドが認識されませんでしたが、環境変数にパスを追加することで無事に稼働(´;ω;`)ウゥゥ
- 環境変数を設定:
- 「スタートメニュー」を右クリックし、「システム」を選択。
- 左側の「システムの詳細設定」をクリック。
- 「環境変数」をクリック。
- 「システム環境変数」の中の「Path」を選択し、「編集」をクリック。
- 「新規」をクリックし、Tesseractのインストールパス(例:
C:\Program Files\Tesseract-OCR)を追加。 - 変更を保存して、全てのウィンドウを閉じます。(ここもとっても大事)
以下のコードを実行します
tesseract --version
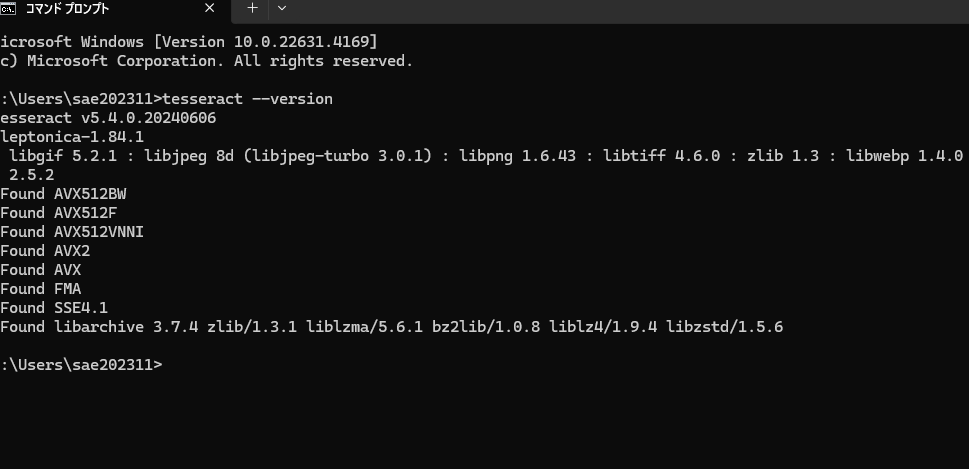
無事に対応できたようです。
ではGitHubのブランチに必要ライブラリをクローンしていきます。それぞれの説明です
- pytesseract:
pytesseract:OCR(光学文字認識)を実行するために必要です。画像からテキストを抽出します。
- Pillow:
Pillow:画像処理を行うためのライブラリです。画像の読み込みや変換、保存などが可能です。
- pandas:
pandas:データ操作や分析を行うためのライブラリです。抽出したテキストをデータフレームとして扱うのに便利です。
- spacy:
spacy:自然言語処理のためのライブラリです。抽出したテキストの解析や処理に使用されます。
- ipywidgets:
ipywidgets:Jupyter Notebookでインタラクティブなウィジェットを作成するためのライブラリです。ユーザーインターフェースを提供します。
リポジトリのクローンをとうとう実行。(重くなるんじゃないかと思うとやる気そげますよね。)
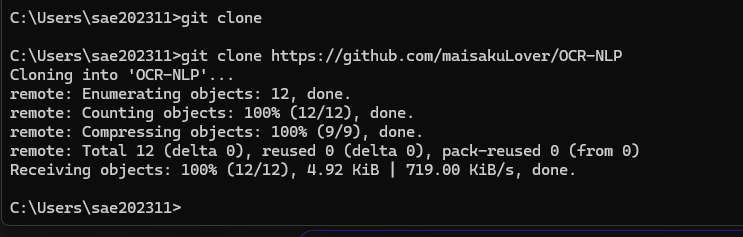
できたところをGitHub Pagesで更新しました

URLは出てきたのですがリンク先は404エラーです。
後にAPIコードがもれるので非公開にしました。
なのでカレントディレクトリを探すためにCMDコマンドを実行します
dirユーザー名の直下にブランチ名でフォルダができていました。
クローンしたリポジトリのフォルダに移動します
cd OCR-NLP変更点を書き込むために、元ファイルを読んでいきます
app.pyファイルの中身はこちら
import pytesseract
from PIL import Image
import pandas as pd
import spacy
import io
from IPython.display import display, HTML
import ipywidgets as widgets
import urllib.parse
# Tesseractのパスを指定(必要に応じて変更してください)
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 日本語モデルをロード
nlp = spacy.load("ja_core_news_sm")
# 画像をアップロードするためのウィジェット
file_upload = widgets.FileUpload(accept='.png, .jpg, .jpeg', multiple=False)
# アップロードされた画像を処理して表示する関数
def process_uploaded_image(change):
uploaded_file = list(change['new'].values())[0]
image_data = uploaded_file['content']
image = Image.open(io.BytesIO(image_data))
display(image)
text = pytesseract.image_to_string(image, lang='jpn')
print("OCRで認識されたテキスト:")
print(text)
data = [{'記事ID': 1, '記事タイトル': 'OCR結果', '作成者': 'ユーザー', '作成日': '2024-10-02', '内容': text, 'コメント': ''}]
df = pd.DataFrame(data)
html_table = df.to_html(index=False, escape=False)
display(HTML(html_table))
csv_data = df.to_csv(index=False, encoding='utf-8')
csv_data = urllib.parse.quote(csv_data)
download_link = f'<a href="data:text/csv;charset=utf-8,{csv_data}" download="ocr_results.csv">ダウンロード</a>'
display(HTML(download_link))
file_upload.observe(process_uploaded_image, names='value')
display(file_upload)
requirements.txt fileは
pytesseract
Pillow
pandas
spacy
ipywidgets
Pythonのバージョン確認です
C:\Users\sae202311>python --version
Python 3.12.4
ここ2.3日ドはまりしていたことがあり。その一文の助けがないことでどれだけ困るか実感してました。メンターのそばにいないとほんと時間がもったいない。学校に通っているはずなのにおかしい。
某エンジニアの神サイトも古い言語ばかり。
日々学んでいかない人には厳しい世界。本当です。
Share this content: