
import requests
from bs4 import BeautifulSoup
url = "https://www.mapion.co.jp/phonebook/M13007/13/"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
links = soup.find_all('a', href=True)
for link in links:
title = link.text.strip()
href = link['href']
print(f"{title}: {href}")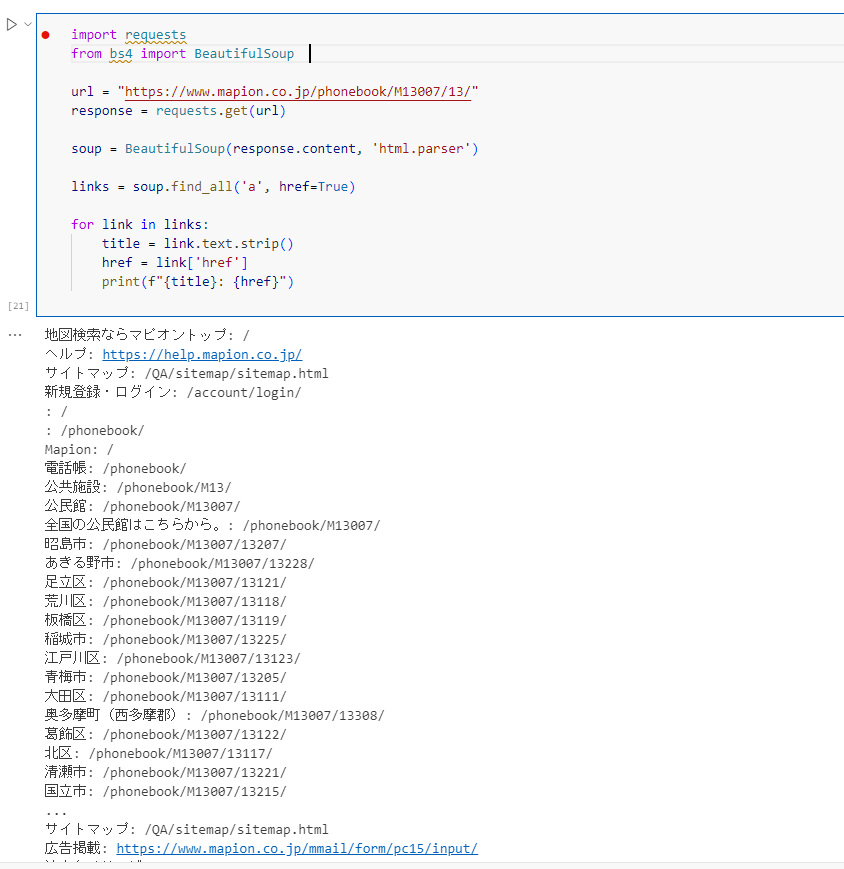
これだと1クリックでとべないので書き直しあくまでユーザーフレンドリー
from bs4 import BeautifulSoup
base_url = "https://www.mapion.co.jp/phonebook/M13007/13/" # base URL (replace with actual URL)
response = requests.get(base_url)
soup = BeautifulSoup(response.content, 'html.parser')
links = [a.get('href') for a in soup.find_all('a', href=True)]
for link in links:
if link.startswith('/phonebook/'):
url = "https://www.mapion.co.jp" + link
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.find('title').text.strip()
print(f"{url}: {title}")
ん~大分気持ちい
それではこのURLをセレニウムに料理してもらいましょう!
セレニウムの説明をします。
セレニウム(Selenium)は、Webアプリケーションの自動テストやブラウザの操作を行うためのオープンソースのフレームワークです。以下は、セレニウムの主な特徴と用途です。
主な特徴
- 多様なブラウザのサポート:
- Chrome、Firefox、Safari、Edge など、主要なウェブブラウザで動作します。
- プログラミング言語のサポート:
- Python、Java、C#、Ruby、JavaScript など、複数のプログラミング言語から利用可能です。
- ユーザーインターフェイスの操作:
- マウスクリック、キーボード入力、ページのスクロールなど、ユーザーが行う操作を自動化できます。
- テストフレームワークとの統合:
- JUnit(Java)、pytest(Python)など、さまざまなテストフレームワークと統合できます。
- 要素の検出と操作:
- Webページ上の様々な要素(ボタン、テキストボックス、リンクなど)を簡単に検出し操作可能です。
主な用途
- 自動テスト:
- ウェブアプリケーションの機能を自動でテストし、開発の初期段階から品質を確保します。
- スクレイピング:
- ウェブサイトからデータを収集するために、自動でブラウザを操作し情報を取得します。
- デモンストレーション:
- アプリケーションの使用方法を示すためのデモを自動化します。
セレニウムは広く使われており、多くの開発者やテスターがウェブアプリケーションのテストや操作に利用しています。
下のコードの各インポート文の説明です。
from selenium import webdriver
- Seleniumのwebdriverモジュールをインポートします。これにより、Webブラウザを自動で操作する機能を使用できます。
from selenium.webdriver.common.by import By
- 要素の検索に使用するByクラスをインポートします。これにより、要素を取得する方法(ID、クラス名、CSSセレクタなど)を指定できます。
from selenium.webdriver.chrome.service import Service
- Chromeブラウザ用のサービスクラスをインポートします。これは、ChromeDriverを管理し、ブラウザを起動するために使用されます。
from selenium.webdriver.support.ui import WebDriverWait
- ウェブドライバーが特定の条件を満たすまで待機するためのWebDriverWaitクラスをインポートします。具体的には、要素が表示されるまで待機するなどの処理に使用します。
from selenium.webdriver.support import expected_conditions as EC
- 期待される条件を指定するためのECモジュールをインポートします。これにより、要素が見える、クリック可能などの条件を指定して待機できます。
from openpyxl import Workbook
- Excelファイルを操作するためのopenpyxlライブラリのWorkbookクラスをインポートします。これにより、Excelファイルの作成や編集が可能になります。
from webdriver_manager.chrome import ChromeDriverManager
- ChromeDriverの自動管理を行うためのChromeDriverManagerをインポートします。このライブラリを使用することで、手動でChromeDriverをダウンロードすることなく、自動的に適切なバージョンをインストールできます。
これらのインポート文を使用することで、Seleniumを使ったブラウザ操作とExcelファイルの操作が簡単に行えるようになります。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from openpyxl import Workbook # openpyxlをインポート
from webdriver_manager.chrome import ChromeDriverManager
# Seleniumのセットアップ
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# Excelファイルのパス
excel_path = r"C:\yourpass"
# 新しいExcelワークブックを作成
workbook = Workbook()
sheet = workbook.active
sheet.title = "Mapion Data"
# リンクのリスト
links = [
"https://www.mapion.co.jp/phonebook/M13007/13207/",
"https://www.mapion.co.jp/phonebook/M13007/13228/",
"https://www.mapion.co.jp/phonebook/M13007/13121/",
"https://www.mapion.co.jp/phonebook/M13007/13118/",
"https://www.mapion.co.jp/phonebook/M13007/13119/",
"https://www.mapion.co.jp/phonebook/M13007/13225/",
"https://www.mapion.co.jp/phonebook/M13007/13123/",
"https://www.mapion.co.jp/phonebook/M13007/13205/",
"https://www.mapion.co.jp/phonebook/M13007/13111/",
"https://www.mapion.co.jp/phonebook/M13007/13308/",
"https://www.mapion.co.jp/phonebook/M13007/13122/",
"https://www.mapion.co.jp/phonebook/M13007/13117/",
"https://www.mapion.co.jp/phonebook/M13007/13221/",
"https://www.mapion.co.jp/phonebook/M13007/13215/",
"https://www.mapion.co.jp/phonebook/M13007/13108/",
"https://www.mapion.co.jp/phonebook/M13007/13210/",
"https://www.mapion.co.jp/phonebook/M13007/13214/",
"https://www.mapion.co.jp/phonebook/M13007/13211/",
"https://www.mapion.co.jp/phonebook/M13007/13219/"
]
try:
for link in links:
# 指定したURLにアクセス
driver.get(link)
# h1要素の取得
headline_element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'headline-ttl'))
)
headline = headline_element.text
# テーブルが存在するまで待機
table = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'list-table'))
)
# テーブル内の行を取得
rows = table.find_elements(By.TAG_NAME, 'tr')
# ヘッダーとしてh1の内容をエクセルに書き込む
sheet.append([headline]) # h1の内容を追加
sheet.append(["リンク", "タイトル"]) # ヘッダー行を追加
# 各行からセルを取得して表示
for row in rows:
# th要素を取得
th_elements = row.find_elements(By.TAG_NAME, 'th')
for th in th_elements:
# a要素が存在する場合、そのリンクとタイトルを取得
if th.find_elements(By.TAG_NAME, 'a'):
link_element = th.find_element(By.TAG_NAME, 'a')
link_href = link_element.get_attribute('href')
title = link_element.get_attribute('title') or link_element.text # title属性がない場合はテキストを使用
# Excelに書き込む
sheet.append([link_href, title])
print(f"Link: {link_href}, Title: {title}") # デバッグ用に出力
# Excelファイルを保存
workbook.save(excel_path)
finally:
# ブラウザを閉じる
driver.quit()
取り出したデータはこちら。
VSCODE上ではよくわかりませんが、エクセルデータ上はタイトルはしっかり個別に収録しています。


で、これで途中経過良好!くらいに思っていたんですがよく考えるとこれを地図上でひょうじさせなくてはなーんにもなりませぬ。。。何にもならないこともないですけどね。
ということで続投します。
Share this content: